机器学习(周志华)读书笔记---第4章
本文共 1116 字,大约阅读时间需要 3 分钟。
4.1 基本流程
决策树的组成: 每个内部节点对应于某个属性上的测试 每个分支对应于该测试的一种可能结果 每个叶节点对应于一个预测结果 决策树的学习目的: 产生一棵泛化能力强,即处理未见示例能力强的决策树 策略: 分而治之,从根节点开始自至叶的递归过程,在每个中间节点寻找一个划分属性。 三种停止条件: (1)当前节点包含的样本全属于同一类别 (2)当前属性集为空或所有样本在所有属性取值相同 (3)当前节点包含的样本集合为空4.2 划分选择
决策树学习的关键在于如何选择最优划分属性,一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的纯度越来越高。4.2.1 信息增益
信息熵是度量样本集合纯度一种常用指标,值越小,样本纯度越高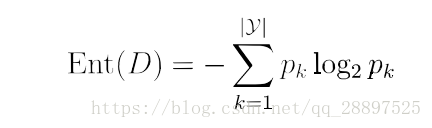 信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化,一般来说,信息增益越大,则意味着使用属性a来划分所获得的纯度提升越大
信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化,一般来说,信息增益越大,则意味着使用属性a来划分所获得的纯度提升越大 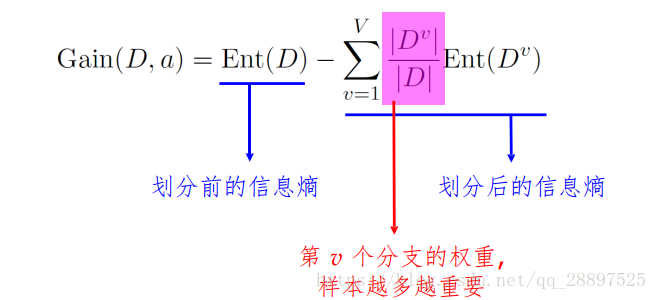 4.2.2 增益率
4.2.2 增益率 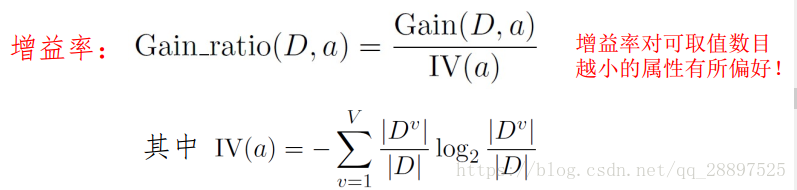 启发式:先从候选划分属性中找出信息增益高于平均水平的,然后从中选择增益率最高的。 4.2.3 基尼指数
启发式:先从候选划分属性中找出信息增益高于平均水平的,然后从中选择增益率最高的。 4.2.3 基尼指数  属性a的基尼指数
属性a的基尼指数 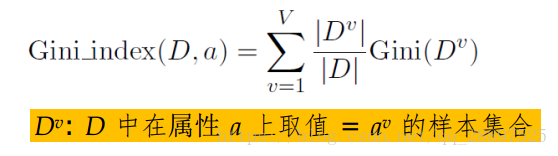 在候选属性中,选择那个使划分后基尼指数最小的属性。 4.3 剪枝处理 划分选择对泛化性能影响有限,剪枝方法和程度对决策树泛化性能的影响更为显著,剪枝是决策树对付过拟合的主要手剪枝段 基本策略: 预剪枝:提前终止某些分支的生长(生长过程中剪枝) 后剪枝:生成一棵完全树,再回头剪枝 剪枝过程中需评估剪枝前后决策树的优劣
在候选属性中,选择那个使划分后基尼指数最小的属性。 4.3 剪枝处理 划分选择对泛化性能影响有限,剪枝方法和程度对决策树泛化性能的影响更为显著,剪枝是决策树对付过拟合的主要手剪枝段 基本策略: 预剪枝:提前终止某些分支的生长(生长过程中剪枝) 后剪枝:生成一棵完全树,再回头剪枝 剪枝过程中需评估剪枝前后决策树的优劣 4.3.1 预剪枝
通过对比划分前后验证集精度来决定是否划分(剪枝后类别标记为训练样例数最多的类别) 风险:欠拟合(决策树桩) 4.3.2 后剪枝 通过剪枝前后精度决定剪枝 训练时间较大,泛化性能较强4.4 连续与缺失
4.4.1 连续值处理 基本思路:连续属性离散化 常见做法:二分法(n个属性可形成n-1个属性划分) 算法步骤: (1) 对样本的n个属性取值得到n-1个中位点作为候选划分点集合 (2)通过采用离散属性值方法,选择最优划分点4.4.2 缺失值处理
仅使用无缺失的样例是对数据的极大浪费 两个问题: Q1.如何在属性值缺失的情况下进行划分属性选择? Q2.给定划分属性,若样本在该属性上缺失值,如何对该样本进行划分? 基本思路:样本赋权,权重划分Q1:

Q2:

4.5 多变量决策树
轴平行划分(针对单变量决策树,在每个非叶节点仅考虑一个划分属性):把每个属性视为坐标空间中的一个坐标轴 目的:改善可理解性 斜的划分边界(针对多变量决策树):非叶节点不再是仅对某个属性,而是对属性的线性组合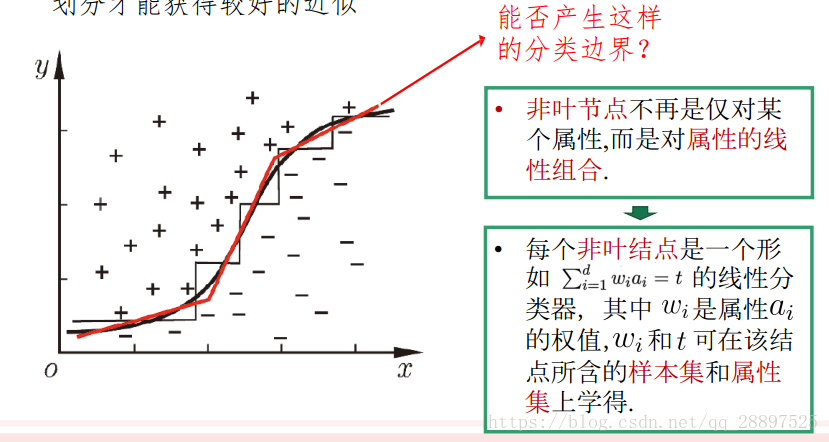 多变量决策树:每个非叶节点不仅考虑一个属性
多变量决策树:每个非叶节点不仅考虑一个属性 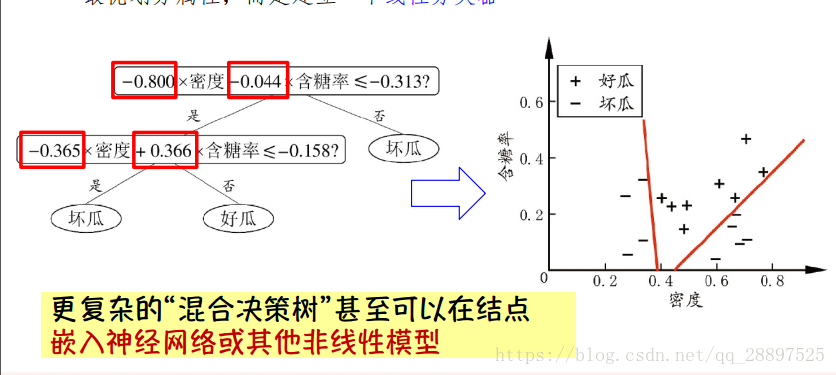
你可能感兴趣的文章
Java虚拟机的内存分配和运行机制(粗谈)
查看>>
web开发之BaseServlet的使用
查看>>
初识Maven
查看>>
Maven分模块构建项目
查看>>
MyBatis初识
查看>>
Mybatis-高级应用
查看>>
MyBatis【进阶详解】
查看>>
面试题集锦(七)
查看>>
结构型设计模式——代理设计模式
查看>>
注解开发——Spring整合dao/service/web
查看>>
Git的应用
查看>>
架构的演进
查看>>
Elastic-Job的基础使用
查看>>
策略过滤器的灵活性分析
查看>>
POI的使用
查看>>
Anaconda和PyCharm的下载、安装和配置
查看>>
Matplotlib绘图工具
查看>>
机器学习之Knn算法
查看>>
Mockito单元测试简述
查看>>
GUAVA的常用方法汇总
查看>>